

Objetivos
- Ampliar el repertorio de herramientas disponibles en Oracle.
- Conocer la funciones analíticas LAG, LEAD, RANK, ROW_NUMBER, FIRST_VALUE, LAST_VALUE, MAX, COUNT y NTILE.
Definición
Las funciones analíticas calculan un valor agregado basado en un grupo de filas. Una función analítica trabaja sobre varias filas y devuelve el resultado en la fila actual. Estas se diferencian de las funciones de grupo/agregadas en que las analíticas devuelven múltiples filas para cada grupo mientras que las grupales o agregadas retornan un valor por grupo.
En Síntesis:
Una función agregada o grupal, agrega datos de varias filas en una sola, por lo cual, reduce el número de filas devueltas por la consulta. Por su parte las funciones analíticas funcionan en subconjuntos de filas, pero no reducen el número de filas devueltas por la consulta.
Las funciones analíticas son el último conjunto de operaciones realizadas en una consulta, a excepción de la cláusula ORDER BY, la cual va al final. Todas las combinaciones y todas las cláusulas WHERE, GROUP BY y HAVING se completan antes de procesar las funciones analíticas. Por lo tanto, las funciones analíticas sólo pueden aparecer en la lista de selección o en la cláusula ORDER BY.
Una función analítica podría ser a su vez una función grupal, como es el caso de COUNT y RANK o una función analítica pura como NTILE.
Nota: No es posible anidar funciones analíticas especificando alguna en la cláusula analytic_clause. Sin embargo, puede especificar una función analítica en una subconsulta y usar otra función analítica sobre ella.
Sintaxis analytic_function:
analytic_function([ arguments ])
OVER (analytic_clause)Sintaxis analytic_clause:
[ query_partition_clause ]
[ order_by_clause [ windowing_clause ] ]Sintaxis query_partition_clause:
PARTITION BY
{ value_expr[, value_expr ]...
| ( value_expr[, value_expr ]... )
}Sintaxis order_by_clause:
ORDER [ SIBLINGS ] BY
{ expr | position | c_alias }
[ ASC | DESC ]
[ NULLS FIRST | NULLS LAST ]
[, { expr | position | c_alias }
[ ASC | DESC ]
[ NULLS FIRST | NULLS LAST ]
]..Sintaxis windowing_clause:
{ ROWS | RANGE }
{ BETWEEN
{ UNBOUNDED PRECEDING
| CURRENT ROW
| value_expr { PRECEDING | FOLLOWING }
}
AND
{ UNBOUNDED FOLLOWING
| CURRENT ROW
| value_expr { PRECEDING | FOLLOWING }
}
| { UNBOUNDED PRECEDING
| CURRENT ROW
| value_expr PRECEDING
}
}Cláusula OVER:
El ámbito de una función analítica se define en una cláusula OVER. OVER es una palabra clave obligatoria para todas las funciones analíticas. Dando () como parámetro, OVER indica el mayor alcance posible.
En términos simples, la cláusula OVER en Oracle especifica la partición o el orden en el que funcionará una función analítica.
Algunas Funciones Analíticas
FIRST_VALUE
Retorna el primer valor en un conjunto ordenado de valores. Si el primer valor del conjunto es nulo, la función devuelve NULL a menos que especifique IGNORE NULLS. Esta configuración es útil para la densificación de datos. Si especifica IGNORE NULLS, FIRST_VALUE devuelve el primer valor no nulo en el conjunto, o NULL si todos los valores son nulos.
Ejemplo:
SELECT
last_name,
department_id,
salary,
FIRST_VALUE(salary) IGNORE NULLS
OVER (PARTITION BY department_id ORDER BY salary ASC) AS lowest_in_dept
FROM hr.employees
ORDER BY department_id;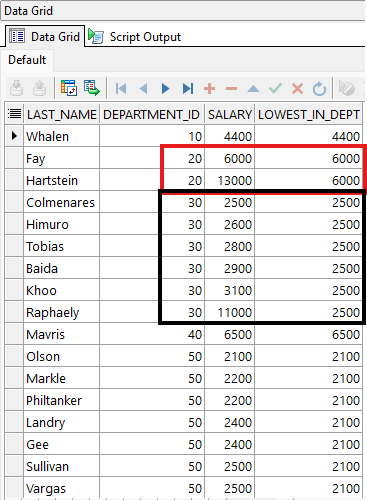
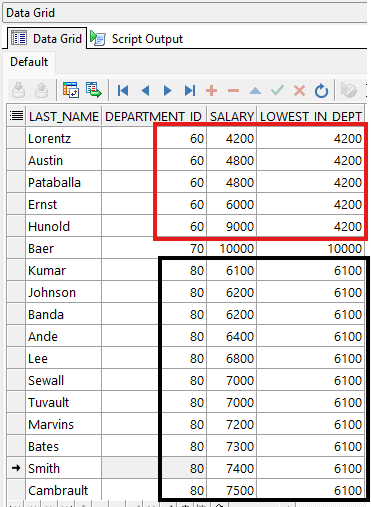
Este ejemplo muestra como usar la función analítica FIRST_VALUE; Notar como la columna lowest_in_dept siempre muestra el salario más bajo para cada departamento de la lista, esto porque la función está ordenada por el salario en forma ascendente.
LAST_VALUE
Funciona de la misma manera que FIRST_VALUE pero con el último valor de un conjunto ordenado de valores.
Ejemplo:
SELECT
last_name,
department_id,
salary,
LAST_VALUE(salary) IGNORE NULLS
OVER (PARTITION BY department_id ORDER BY salary ASC) AS last_found_in_dept
FROM hr.employees
ORDER BY department_id;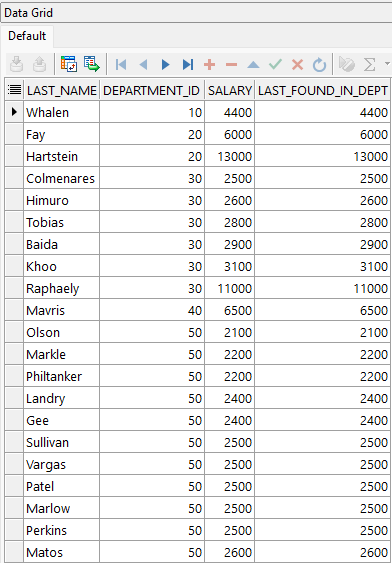
LAST_VALUE, a diferencia de la función FIRST_VALUE muestra el último valor encontrado dentro del marco de filas definido en la cláusula analítica. Por esta razón el ejemplo no se presta para mostrar el salario más alto por cada departamento de la lista, ya que el mismo equivale al último valor de la lista ordenada por el salario en forma ascendente.
MAX
La función analítica MAX devuelve el valor máximo de una expresión dentro de una partición definida por la cláusula OVER. A diferencia de la función de agregación tradicional, la versión analítica no reduce el conjunto de resultados, sino que muestra el valor máximo para cada fila, manteniendo el detalle del resultado.
Ejemplo:
SELECT
last_name,
department_id,
salary,
MAX(salary)
OVER (PARTITION BY department_id ORDER BY salary DESC) AS highest_in_dept
FROM hr.employees
ORDER BY department_id, salary;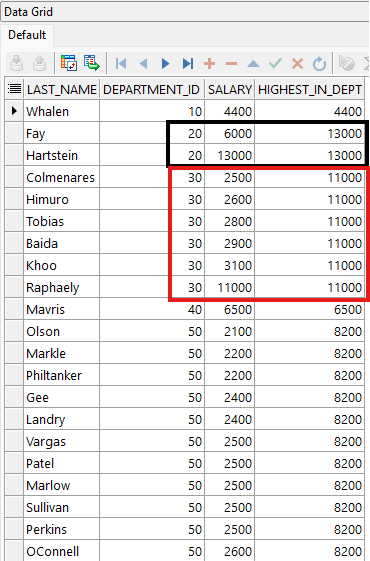
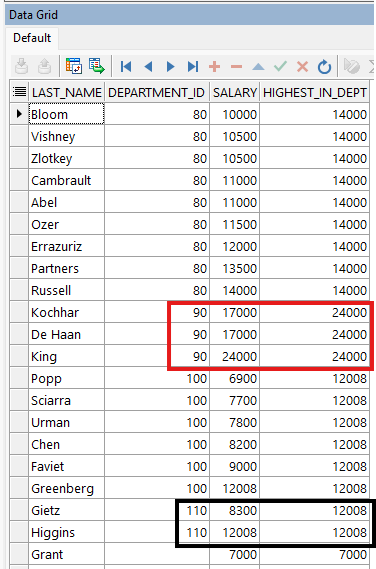
Este ejemplo muestra el resultado opuesto al mostrado con la función FIRST_VALUE. La columna HIGHEST_IN_DEPT siempre muestra el salario más alto para cada departamento de la lista.
RANK
Como función analítica, calcula el rango de cada fila devuelta de una consulta con respecto a las otras filas retornadas.
Ejemplo:
SELECT
last_name,
salary,
commission_pct,
RANK()
OVER (PARTITION BY department_id
ORDER BY salary DESC, commission_pct DESC) "Rank"
FROM employees
WHERE department_id = 80;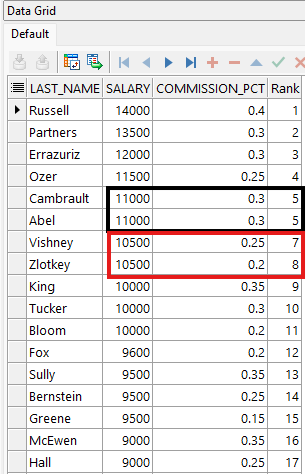
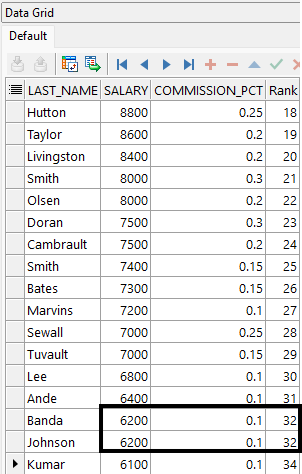
Este ejemplo muestra el ranking de beneficios del departamento 80, se evalúa el salario y la comisión de siguiente manera:
- El ranking se calcula por salario descendente y, en caso de empate, por commission_pct descendente.
- Los empleados con mejores valores aparecen con menor número de Rank (1 = mejor).
En la imagen podemos ver como Wishney y Zlotkey tienen el mismo salario, pero diferente comisión → reciben rangos distintos (7 y 8). Banda y Johnson tienen exactamente los mismos valores → ambos son rank 32, y el siguiente salta a 34.
COUNT
Como función analítica se utiliza para contar filas dentro de una partición definida por la cláusula OVER. A diferencia de la función de agregación tradicional, la versión analítica no reduce el conjunto de resultados, sino que devuelve un valor de conteo para cada fila, respetando el contexto de partición y orden.
Ejemplo:
SELECT
department_id,
COUNT(*)
OVER (PARTITION BY department_id) Total_Dept,
job_id,
COUNT(*)
OVER (PARTITION BY job_id) Total_Job
FROM hr.employees
ORDER BY department_id, job_id;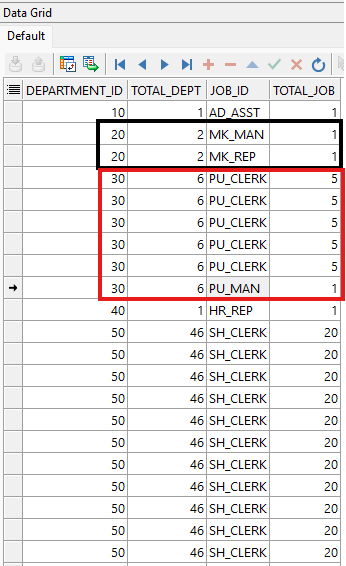
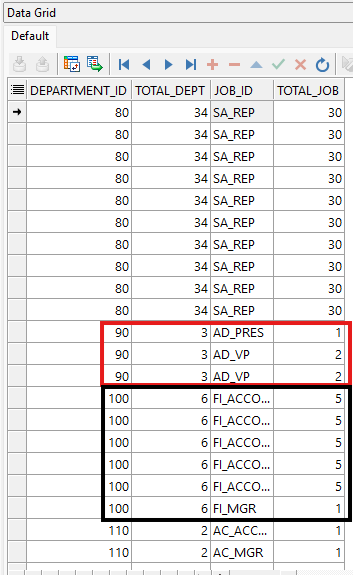
Este ejemplo muestra como usar la función analítica COUNT. Total_Dept indica cuántos empleados pertenecen al mismo department_id de cada fila. Total_Job muestra cuántos empleados comparten el mismo job_id.
ROW_NUMBER
Asigna un número único a cada fila a la que se aplica (ya sea cada fila de la partición o cada fila devuelta por la consulta), en la secuencia ordenada de filas especificada en el order_by_clause, comenzando por 1.
Ejemplo:
SELECT
department_id,
last_name,
employee_id,
ROW_NUMBER()
OVER (PARTITION BY department_id ORDER BY employee_id ASC) AS emp_id
FROM hr.employees;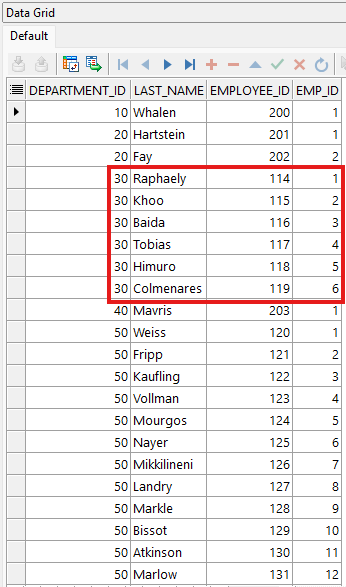
El ejemplo muestra como usar la función analítica ROW_NUMBER; Notar que la columna emp_id muestra el orden o posición que representa el empleado en su departamento (ordenado por numero de empleado ascendente).
NTILE
Divide un conjunto de datos ordenados en la cantidad de cubos(buckets) indicados por el parámetro: expr y asigna el número de cubos apropiado a cada fila. Los cubos están numerados del 1 al valor expr. El valor expr debe ser a una constante positiva para cada partición. Oracle espera un número entero, y si expr es una constante NONINTEGER(no entera), Oracle trunca el valor a un entero. El valor de retorno es NUMBER.
Ejemplo:
SELECT
last_name,
salary,
NTILE(4)
OVER (ORDER BY salary DESC) AS quartile
FROM employees
WHERE department_id = 100;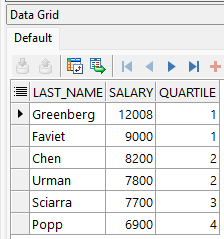
La consulta muestra cómo se distribuyen los empleados del departamento 100 en cuartiles de salario.
- Quartile 1 → los mejor pagados.
- Quartile 4 → los peor pagados.
- Los cuartiles intermedios agrupan los salarios medios.
LAG
Permite acceder al valor de una columna en una fila anterior a la actual dentro de la misma partición. Se utiliza para comparar el valor actual con el previo en una secuencia ordenada.
Ejemplo:
SELECT
last_name,
department_id,
salary,
LAG(salary)
OVER (PARTITION BY department_id ORDER BY salary ASC) AS prev_in_dept
FROM hr.employees
ORDER BY department_id, salary;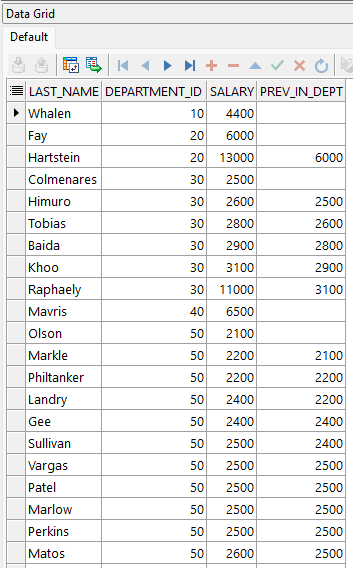
Para el ejemplo de la función LAG usamos el departamento y salario del empleado. Notar como la columna PREV_IN_DEPT muestra el salario del empleado de la fila anterior entro del mismo departamento, por lo cual el primer empleado mostrado por departamento tiene este campo nulo.
LEAD
Permite acceder al valor de una columna en una fila posterior a la actual dentro de la misma partición. Es útil para comparar el valor actual con el siguiente en una secuencia ordenada.
Ejemplo:
SELECT
last_name,
department_id,
salary,
LEAD(salary)
OVER (PARTITION BY department_id ORDER BY salary ASC) AS next_in_dept
FROM hr.employees
ORDER BY department_id, salary;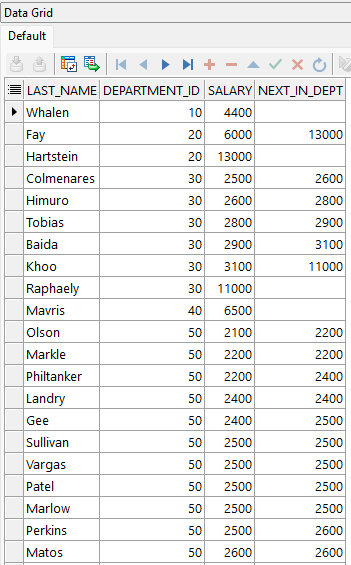
Para el ejemplo de la función LEAD modificamos el ejemplo de LAG. Notar como la columna NEXT_IN_DEPT muestra el salario del empleado de la fila siguiente entro del mismo departamento, por lo cual el último empleado mostrado por departamento tiene este campo nulo.