

Objetivos
- Utilizar Expresiones Regulares en SQL para buscar, hacer corresponder y sustituir cadenas siempre en términos de expresiones normales/regulares.
- Ver el uso de las funciones: REGEXP_LIKE, REGEXP_REPLACE, REGEXP_INSTR, REGEXP_SUBSTR y REGEXP_COUNT.
NOTA: Usamos como ejemplo la Base de Datos: ORCL, la cual viene por defecto en cualquier versión de ORACLE.
Descripción
Las expresiones regulares están disponibles en la base de datos Oracle a partir de la versión 10g. La implementación cumple con el estándar POSIX (Sistema Operativo Portátil para UNIX), controlado por el IEEE (Instituto de Ingenieros en Electricidad y Electrónica), para la semántica y la sintaxis de correspondencia de datos ASCII. Las capacidades multilingües de Oracle amplían las capacidades de correspondencia de los operadores más allá del estándar POSIX. Las expresiones regulares son un método para describir patrones sencillos y complejos de búsqueda y manipulación.
La búsqueda y manipulación de cadenas de caracteres suponen un amplio porcentaje de la lógica de una aplicación basada en la Web. El uso va desde la simple búsqueda de las palabras “San Francisco” en un texto especificado, pasando por la compleja extracción de todas las direcciones URL del texto, hasta la búsqueda más compleja de todas las palabras cuyo segundo carácter sea una vocal.
Si se une al SQL nativo, el uso de expresiones regulares permite operaciones muy potentes de búsqueda y de manipulación de cualquier dato almacenado en una Base de Datos Oracle. Puede utilizar esta función para solucionar fácilmente problemas que de otro modo resultarían muy complejos de programar.
Los Metacaracteres:
| Símbolo | Descripción |
| * | Se corresponde con cero o más incidencias. |
| | | Operador de modificación para especificar correspondencias alternativas. En pocas palabras equivale a ‘o’. Eje: 8|5 = 8 o 5. |
| ^/$ | ^: representa inicio de línea; $ es fin de línea. |
| [ ] | Expresión entre corchetes para una lista de correspondencia que se corresponde con cualquiera de las expresiones representadas en la lista. |
| {m} | Se corresponde exactamente m veces. |
| {m,n} | Se corresponde al menos m veces, pero no más de n veces. |
| [: :] | Especifica una clase de carácter y se corresponde con cualquier carácter de esa clase. |
| \ | Puede tener 4 significados diferentes: 1. Se representa a sí mismo. 2. Presenta el siguiente carácter. 3. Introduce un operador. 4. No hace nada. |
| + | Se corresponde con una o más incidencias. |
| ? | Se corresponde con cero o una incidencia. |
| . | Se corresponde con cualquier carácter del juego de caracteres soportado, excepto NULL. |
| () | Expresión de agrupamiento, que se trata como subexpresión única. |
| [==] | Especifica clases de equivalencia. |
| \n | Referencia a expresión anterior. |
| [..] | Especifica un elemento de intercalación como, por ejemplo, un elemento de varios caracteres. |
| \d | Equivale a un Digito (Carácter Numérico). Equivalente a [[:digit:]]. |
| \D | Equivale a un Carácter no Numérico. |
| \w | Representa un carácter alfanumérico. Incluye el underscore( _) |
| \W | Representa un Carácter no letra. |
| \A | Equivale al inicio de una cadena de caracteres o el fin de una cadena antes de una nueva línea. |
| \Z | Representa el fin de una cadena |
| \s | Equivale a un espacio en blanco. |
| \S | Equivale a un no espacio en blando. |
Los metacaracteres son caracteres especiales que tienen un significado especial como, por ejemplo, un comodín, un carácter de repetición, un carácter de no correspondencia o un rango de caracteres. Puede utilizar varios símbolos de metacaracteres predefinidos en la correspondencia de patrones.
Clases de Caracteres POSIX:
Ya indicamos que es posible usar: [::] para especificar clases de caracteres. Estas clases resultan bastante útiles en escenarios multilenguajes, esto debido a que cada lenguaje tiene un conjunto diferente de caracteres que pueden no existir en otros idiomas. El estándar POSIX ofrece las clases de carácter portátiles: ‘[::]’ que presentamos a continuación:
| Clase Carácter | Definición |
| [:alnum:] | Todos los caracteres alfanuméricos. |
| [:alpha:] | Todos los caracteres alfabéticos. |
| [:blank:] | Todos los caracteres de espacio en blanco. |
| [:cntrl:] | Todos los caracteres de control (no imprimibles). |
| [:digit:] | Todos los dígitos numéricos. |
| [:graph:] | Conjunto que agrupa estas clases: [:punct:], [:upper:], [:lower:],[:digit:]. |
| [:lower:] | Todos los caracteres alfabéticos en minúscula. |
| [:print:] | Todos los caracteres imprimibles. |
| [:punct:] | Todos los signos de puntuación. |
| [:space:] | Todos los caracteres de espacio (no imprimibles). |
| [:upper:] | Todos los caracteres alfabéticos en mayúscula. |
| [:xdigit:] | Todos los caracteres hexadecimales válidos. |
Nota: Oracle es compatible con las clases de caracteres antes presentadas, basado en la definición de clase de carácter establecidos en el parámetro de inicialización NLS_SORT.
Funciones de Expresiones Regulares
La Base de Datos Oracle 10g proporciona un juego de funciones SQL que se pueden utilizar para buscar y manipular cadenas mediante expresiones regulares. Puede utilizar estas funciones en cualquier tipo de datos que contenga datos de caracteres como, por ejemplo, CHAR, NCHAR, CLOB, NCLOB, NVARCHAR2 y VARCHAR2. Una expresión regular debe ir entre comillas simples. Esto asegura que toda la expresión sea interpretada por la función SQL y puede mejorar la legibilidad del código.
| Nombre de Función | Descripción |
| REGEXP_LIKE | Parecido al operador LIKE, pero realiza una correspondencia de expresiones regulares en lugar de una correspondencia de patrones sencillos. Esta función busca un patrón en una columna de caracteres. Puede utilizarla en la cláusula WHERE de una consulta para devolver las filas que se correspondan con la expresión regular que se especifique. |
| REGEXP_REPLACE | Busca un patrón de expresión regular y lo sustituye por una cadena de sustitución |
| REGEXP_INSTR | Busca en una cadena especificada un patrón de expresión regular y devuelve la posición en la que se encuentra la correspondencia |
| REGEXP_SUBSTR | Busca un patrón de expresión regular dentro de una cadena especificada y devuelve la subcadena con la correspondencia |
| REGEXP_COUNT | Retorna la cantidad de veces que un patrón de expresión regular aparece dentro de una cadena dada. Función introducida en la versión 11g. |
Sintaxis:
REGEXP_LIKE (srcstr, pattern [,match_option])REGEXP_INSTR (srcstr, pattern [, position [, occurrence
[, return_option [, match_option]]]])REGEXP_SUBSTR (srcstr, pattern [, position
[, occurrence [, match_option]]])REGEXP_REPLACE(srcstr, pattern [,replacestr [, position
[, occurrence [, match_option]]]])REGEXP_COUNT(srcstr, pattern [, position [, match_option]])En la sintaxis:
| srcstr | Cadena de origen sobre la cual se aplica la expresión regular; es el texto que será evaluado, buscado o manipulado por la función REGEXP. |
| pattern | Expresión Regular |
| occurrence | Incidencia que se buscará |
| position | Punto de partida de la búsqueda |
| return_option | Posición inicial o final de la incidencia |
| replacestr | Cadena de caracteres que sustituye al patrón |
| match_option | Opción para cambiar la correspondencia por defecto; puede incluir uno o más de los siguientes valores:“c” —utiliza una correspondencia sensible a mayúsculas/minúsculas (por defecto)“I” —utiliza una correspondencia no sensible a mayúsculas/minúsculas“n” —permite el operador de correspondencia con cualquier carácter“m” —trata la cadena de origen como varias líneas |
Ejemplos
CREATE TABLE tabla_caracteres
(id_caract NUMBER,
caracteres VARCHAR2(20),
tipo_caract VARCHAR2(8));El script anterior crea la tabla tabla_caracteres, la cual usaremos para nuestros futuros ejemplos.
DECLARE
v_cadena VARCHAR2(100) := '@#$12345678987654abcdef~`!%^&./;:"?><ghi98jQSXCYJklmnñop*()_+=-[]\}{|6789,HRFDqrstuvwxyz';
v_sub_cadena VARCHAR2(100);
BEGIN
FOR i IN 1..30 LOOP
v_sub_cadena := SUBSTR(v_cadena, TRUNC(DBMS_RANDOM.VALUE(1,77)),10);
INSERT INTO tabla_caracteres(id_caract, caracteres)
VALUES(i,v_sub_cadena);
END LOOP;
COMMIT;
END;Usamos un Bloque Anónimo de PL/SQL para insertar 30 registros a nuestra tabla. Registro a continuación:
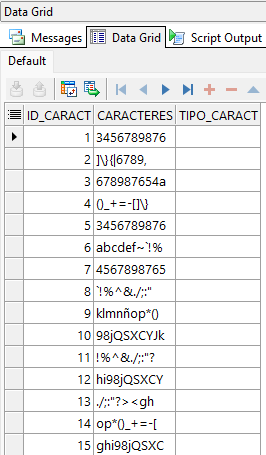
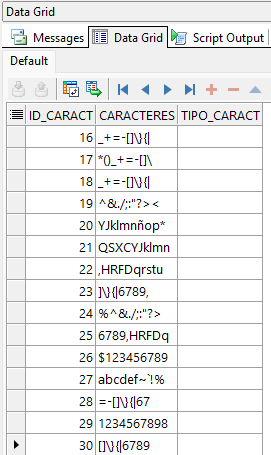
SELECT *
FROM tabla_caracteres
WHERE REGEXP_LIKE(caracteres,'^\d+$');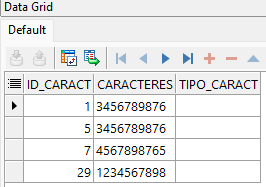
El ejemplo anterior muestra el uso de la función REGEXP_LIKE; La consulta retorna los registros que solo tienen caracteres numéricos.
- ^\d = indica que la cadena debe iniciar con números;
- + = indica que habrá n ocurrencias del pasado patrón.
- $ = especifica que la cadena debe concluir con el patrón que antecede el signo $.
SELECT *
FROM tabla_caracteres
WHERE REGEXP_LIKE(caracteres,'^\D+$');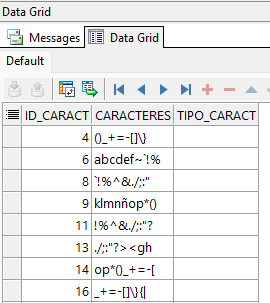
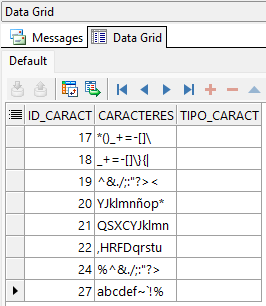
Contrario al último ejemplo, este muestra los registros que no tienen caracteres numéricos.
SELECT *
FROM tabla_caracteres
WHERE REGEXP_LIKE(caracteres,'^\w+$')
AND REGEXP_LIKE(caracteres, '^[^[:digit:]]+$');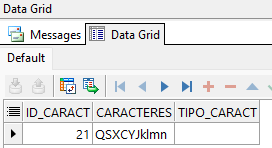
Esta consulta muestra el único registro que solo tienen caracteres alfabéticos. Como ‘\w’ incluye números, agregamos la condición de que sea no numérico: [^[:digit:]]. Osea, que sea alfanumérico y no numérico; solo alfa = letras.
UPDATE tabla_caracteres c
SET c.tipo_caract =
(SELECT
CASE
WHEN REGEXP_LIKE(c.caracteres,'^\d+$') THEN 'NUMERICO'
WHEN REGEXP_LIKE(c.caracteres,'^\w+$')
AND REGEXP_LIKE(c.caracteres, '^[^[:digit:]]+$') THEN 'LETRAS'
WHEN REGEXP_LIKE(c.caracteres, '^[[:punct:]]+$') THEN 'SIGNOS'
ELSE 'MIXTO'
END
FROM dual);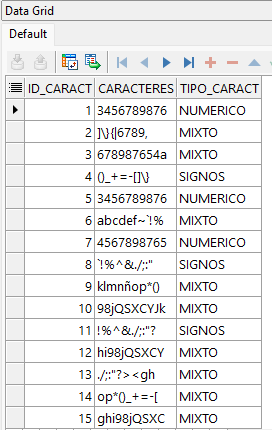
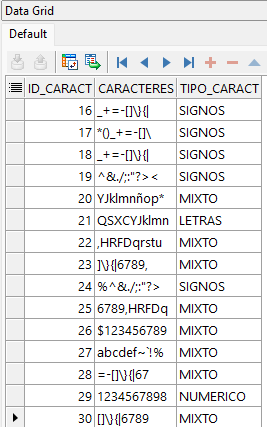
En este ejemplo actualizamos el campo tipo_caract con uno de los valores: LETRAS, NUMERICO, SIGNOS, MIXTO de acuerdo al contenido del campo caracteres. Notar el uso una subconsulta correlacionada y la función REGEXP_LIKE combinada con un CASE para así asignar el tipo indicado a cada registro.
SELECT
id_caract
, caracteres
, tipo_caract
, REGEXP_COUNT(caracteres,'[[:digit:]]') AS cantidad_numeros
, REGEXP_COUNT(caracteres,'[[:alpha:]]') AS cantidad_alfabetica
, REGEXP_COUNT(caracteres,'[[:alnum:]]') AS cantidad_alfanumerica
, REGEXP_COUNT(caracteres,'[[:punct:]]') AS cantidad_signos
FROM tabla_caracteres;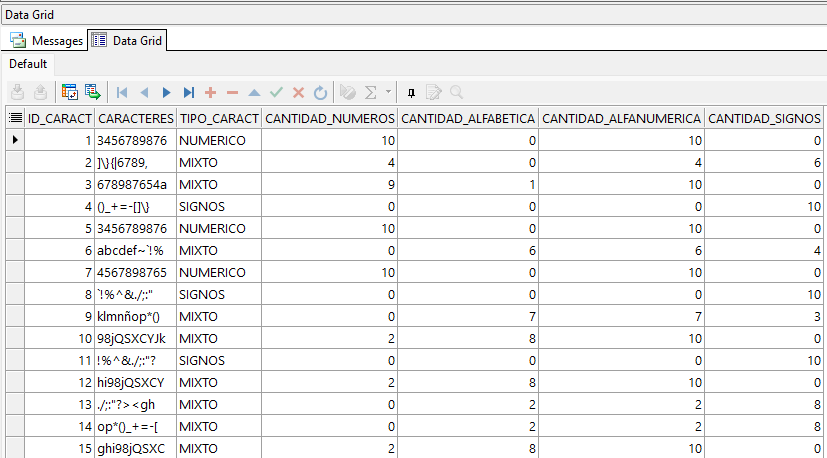
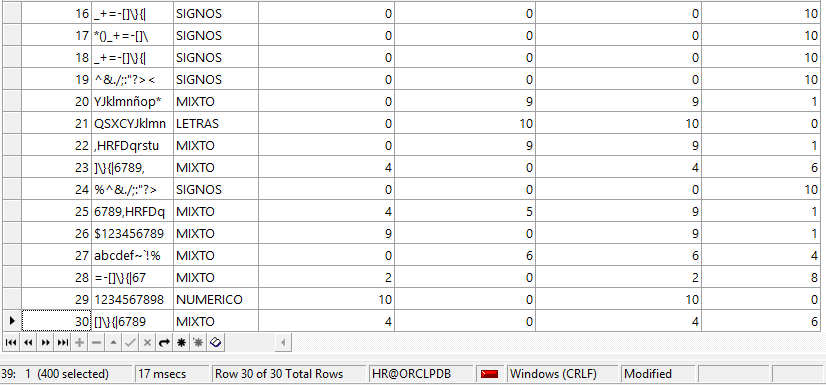
En este ejemplo usamos la función REGEXP_COUNT para contabilizar la cantidad de caracteres numéricos [:digit:], alfabéticos [:alpha:], alfanuméricos [:alnum:] y signos de puntuación [:punct:] de cada registro.
SELECT street_address AS "Direccion"
, REGEXP_INSTR(street_address,'[^[:alpha:]]') AS "Caracter No Alfa"
FROM locations
WHERE REGEXP_INSTR(street_address,'[^[:alpha:]]')> 1;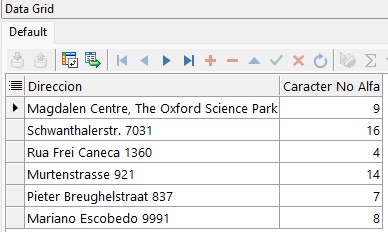
En este ejemplo, la función REGEXP_INSTR se utiliza para buscar la calle con el fin de encontrar la ubicación del primer carácter no alfabético. La búsqueda se realiza sólo en las calles que no empiecen por un número. Observe que [:<class>:] implica una clase de carácter y se corresponde con cualquier carácter de esa clase; [:alpha:] se corresponde con cualquier carácter alfabético.
En la expresión utilizada en la consulta es: ‘[^[:alpha:]]’:
- [ = inicia la expresión.
- ^ = indica NO.
- [:alpha:] = indica la clase de carácter alfabético.
- ] = finaliza la expresión.
SELECT street_address AS "Direccion"
, REGEXP_SUBSTR(street_address , ' [^ ]+ ') AS "Calle"
FROM locations;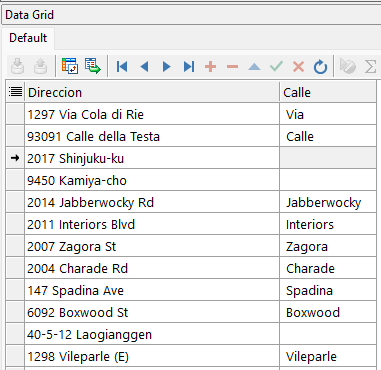
En este ejemplo, los nombres de calle se extraen de la tabla LOCATIONS. Para ello, se devuelve el contenido de la columna STREET_ADDRESS que está entre los 2 primeros espacios(null si no contiene 2 espacios) mediante la función REGEXP_SUBSTR.
SELECT caracteres
, REGEXP_REPLACE(caracteres, '[[:upper:]]', '.') "No Mayúsculas"
FROM tabla_caracteres
WHERE REGEXP_LIKE(caracteres, '^[[:alnum:]]+$'); 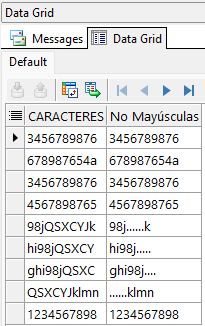
El ejemplo primero filtra los registros que contienen solo caracteres alfanuméricos y en ellos reemplaza los caracteres alfabéticos en mayúscula por puntos ‘.’.
En la expresión: ‘[[:upper:]]’
- [ =inicia la expresión.
- [:upper:] = indica caracteres alfabéticos en mayúscula
- ] =finaliza la expresión.
En la expresión: ‘^[[:alnum:]]+$’
- ^[[:alnum:]] = indica el patron de inicio(alfanumérico).
- + = indica que habrá n ocurrencias del pasado patrón.
- $ = especifica que la cadena debe concluir con el patrón que antecede el signo $.
Restricciones de Integridad de Datos con Expresiones Regulares
Las expresiones regulares también pueden ser utilizadas en restricciones de control (CONSTRAINTS). Esto nos permite establecer ciertos patrones de formato para los datos que deseamos permitir en las tablas de la base de datos.
Ejemplos
CREATE TABLE contactos
(id_contacto NUMBER
, nombre VARCHAR2(30)
, telefono VARCHAR2(10)
, correo VARCHAR2(50));Para visualizar el uso de expresiones regulares en restricciones de Integridad de datos creamos la tabla contactos.
ALTER TABLE contactos
MODIFY (
nombre
CONSTRAINT ck_nombre_contact
CHECK
(
REGEXP_LIKE(nombre, '^[[:alpha:]]{2,5}[[:alpha:][:blank:]]+$')
)
, telefono
CONSTRAINT ck_telefono_contact
CHECK
(
REGEXP_LIKE(telefono, '^8[024]9[[:digit:]]{7}')
)
, correo
CONSTRAINT ck_correo_contact
CHECK
(
REGEXP_LIKE(correo, '^[[:alpha:]][[:alnum:]]{1,25}@[[:alpha:]]{5,19}.[[:alpha:]]{2,3}')
));Aquí alteramos la tabla para agregarle unos CONSTRAINT a sus columnas de datos.
- Para el nombre los usuarios solo podrán digital caracteres alfabéticos y/o espacios en blanco:
- ^[[:alpha:]]{2,5} que inicie con por lo menos 2 caracteres alfabéticos.
- [[:alpha:][:blank:]]+$ que contenga caracteres alfabéticos o espacios, hasta el final.
- Para el teléfono solo se podrá digital números de 10 dígitos que inicien con 809, 829 o 849:
- ^8 que inicio con un 8.
- [024] permite uno de estos tres dígitos: 0, 2 o 4.
- 9 debe haber un 9 en esta posición.
- [[:digit:]]{7} indica la presencia de 7 dígitos numéricos seguidos.
- Para el correo, las entradas validas iniciaran con un carácter alfabético, seguido por un máximo de 25 caracteres alfanuméricos(mínimo 1), seguidos por una @, luego un máximo de 19 caracteres alfabéticos(mínimo 5), luego un punto ‘.’ y por último un máximo de 3 caracteres alfabéticos(mínimo 2).
- ^[[:alpha:]] inicia con un carácter alfabético.
- [[:alnum:]]{1,25} de 1 a 25 caracteres alfanuméricos.
- @ presencia de una Arroba.
- [[:alpha:]]{5,19} de 5 a 19 caracteres alfabéticos.
- . presencia de un punto.
- [[:alpha:]]{2,3} de 2 a 3 caracteres alfabéticos.
INSERT INTO contactos(nombre)
VALUES(' Juan');INSERT INTO contactos(nombre)
VALUES('1Manuel Perez');Los INSERT anteriores no cumplen con la restricción de campo nombre. Su ejecución genera error.
INSERT INTO contactos(nombre)
VALUES('Lily Perez');INSERT INTO contactos(nombre)
VALUES('Jose');Los dos INSERT anteriores son ejecutados con éxito ya que sus cadenas de caracteres están acorde con la restricción del campo nombre.
INSERT INTO contactos(telefono)
VALUES('8499542357');El INSERT anterior cumple perfectamente con la restrincción del campo telefono. Su ejecución es exitosa.
INSERT INTO contactos(telefono)
VALUES('8399542357');El INSERT anterior genera error debido a que no está acorde a la restricción de integridad del campo telefono.
INSERT INTO contactos(correo)
VALUES('0antonio@gmail.com');INSERT INTO contactos(correo)
VALUES(' marta@yahoo.com');En ambos ejemplos anteriores las cadenas de caracteres a insertar no cumplen con la restricción de integridad del campo correo. Generan error.
INSERT INTO contactos(correo)
VALUES('papo@outlook.com');INSERT INTO contactos(correo)
VALUES('hombrecorreo12@valido.do');Los dos últimos INSERT contienen cadenas de caracteres que están acorde a la restricción de integridad del campo correo. La inserción es exitosa.